Empirical Evaluation of Pre-trained Transformers for Human-Level NLP: The Role of Sample Size and Dimensionality
TLDR: How many transformer dimensions are required for your task?
Working on human-level NLP and looking for a simple way to effectively improve transformer-based approaches? We’ve empirically investigated and found some useful options: We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Often, task-specific models can achieve results comparable to the best performance with just 1/12 of the embedding dimensions. Use the form above to download our recommended RoBERTa dimensionality reduction given your (a) number of training samples, and (b) task domain.
How to improve the performance of contextual embeddings in low sample settings?
It is very simple, yet effective. Training PCA to reduce the dimensions of the transformer on unlabeled domain data improves the performance over pre-trained representations (or fine-tuning to the task). Results from a thorough investigation using bootstrapped sampling, demonstrate using such a transformation typically produces accuracies in downstream tasks as good or significantly better than using the second-to-last layer or fine-tuning the transformer at the message-level. The code to do the dimensionality reduction (transformation matrix or DLATK picklefile) are available by selecting your training data size and task domain above.
Key Links
What are Human-Level NLP tasks?
Human-level NLP tasks, rooted in computational social science, focus on estimating characteristics about people from their language use patterns. Examples of these tasks include personality trait prediction, mental health assessment, and demographic estimation. Using transformers for these tasks enables them to not only capture the words used but the semantics given the context in which they occur and the person behind it. However, these tasks often only have training datasets numbering in the hundreds.
What are the challenges of using transformers in these tasks?
Transformer models yield representations of over 20,000 dimemensions! (i.e. 1024 hidden-state size by 24 layers). Even just using one layer often means the number of dimensions are larger than the number training examples (often numbering only a few hundred). Further, transformers are pre-trained at document level, and yet these tasks run over multiple documents. In fact, when fine-tuning transformers (without making significant architectural changes) for these tasks, results are worse than just the pre-trained model. The best models in shared tasks use something akin to the average document-level embeddings across all posts of a user (e.g. see CLPsych-2019 shared task).
Why are these tasks important?
Natural language is human-generated. Understanding human attributes associated with language can enable applications that improve human life, such as producing better mental health assessments that could ultimately save lives. Mental health conditions, such as depression, are widespread and many suffering from such conditions are under-served with only 13 - 49% receiving minimally adequate treatment (Kessler et al., 2003; Wang et al., 2005). We believe this technology, when used in collaboration with mental health care professionals, offers the potential to broaden the coverage of mental health care to such populations where resources are currently limited.
Further, for the advancement of NLP in general, these tasks present a challenge in modeling: The samples from a person are composed of a greater variety of subject matters (posts) with limited high signal messages amidst the noise. Some of the human-level tasks are unique in not having a single ground truth but a set of accepted outcomes - making it challenging to interpret metrics like accuracy. Hence these tasks provide an alternative evaluation of the semantics captured by the standard LMs, i.e., understanding the person behind the text rather than assuming a single view of what the text expresses. Fewer features without loss of accuracy generally suggests greater generalization.
Which transformer model is suited for these tasks?
Most of these tasks are based on social media language. Hence a model fine-tuned to the social media domain would work the best. However, amongst the popularly used pre-trained models, we find RoBERTa to offer the best performance in these tasks.
Which reduction method is preferable?
Amongst the reduction methods based on the techniques of non-linear autoencoders and Singular Value Decomposition (SVD), we find that PCA and Non-negative Matrix Factorization (NMF) produce consistently better performance over the rest. We also find that PCA is better than NMF in handling longer sequences of texts, which is depicted in the figure below.
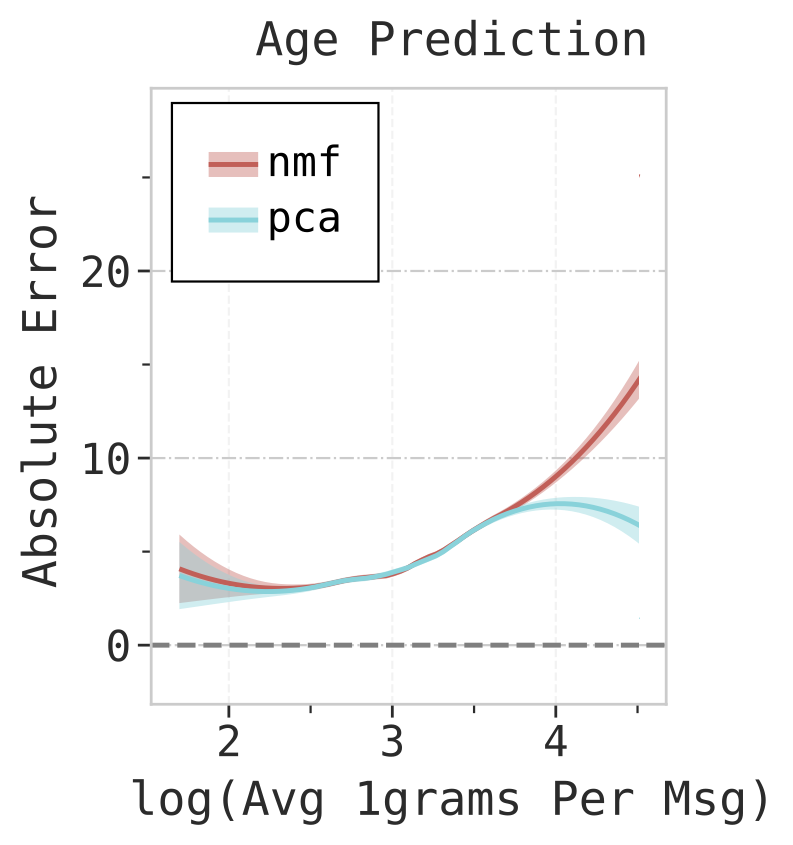
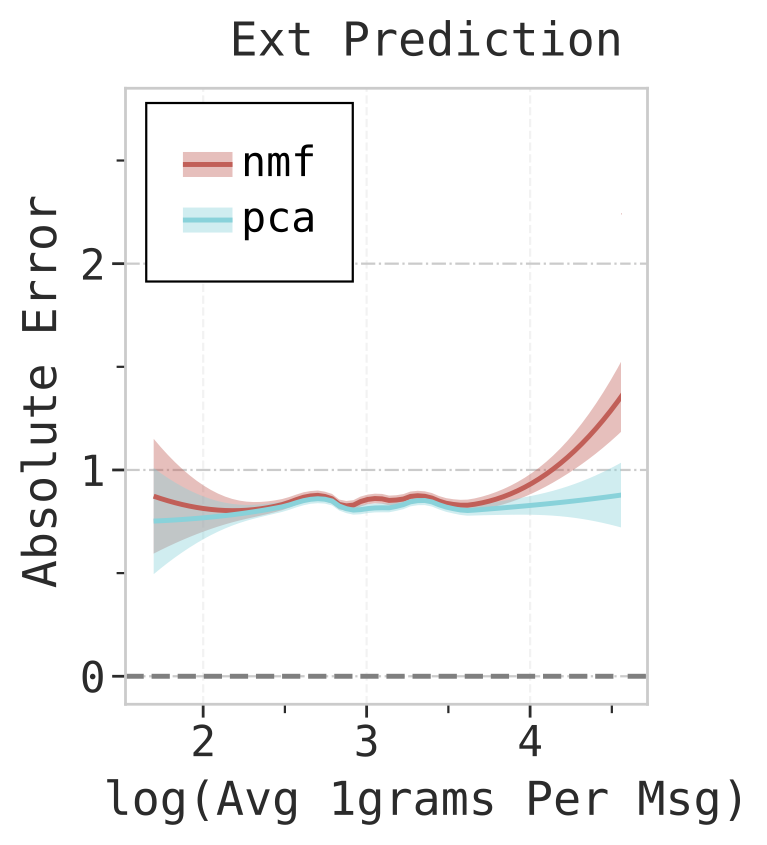
What are the full results on the ideal number of dimensions per task domain?
The number of dimensions required to obtain the best performance is summarized in the table below. We find that many of these tasks only require 1/6th or 1/12th of the hidden dimensions to achieve best performance.
| Number of training samples | Demographic Tasks | Personality Tasks | Mental Health Tasks |
|---|---|---|---|
| 50 | 16 | 16 | 16 |
| 100 | 128 | 16 | 22 |
| 200 | 512 | 32 | 45 |
| 500 | 768 | 64 | 64 |
| 1000 | 768 | 90 | 64 |
| 2000 | 768 | 90 | 64 |
| 5000 | 768 | 181 | 64 |
| 10000 | 768 | 181 | 64 |
How to cite this:
@inproceedings{v-ganesan-etal-2021-empirical,
title = "Empirical Evaluation of Pre-trained Transformers for Human-Level {NLP}: The Role of Sample Size and Dimensionality",
author = "V Ganesan, Adithya and Matero, Matthew and Ravula, Aravind Reddy andVu, Huy and Schwartz, H. Andrew",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "aclanthology.org/2021.naacl-main.357/",
pages = "4515--4532"}
Footnotes
2 Learn more about the pre-trained reduction models here.